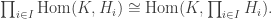Polynomial Rings
A polynomial over a ring R is an expression of the form:

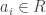

Let’s get some standard terminology out of the way. The element ai is called the coefficient of xi. The largest n for which an ≠ 0 is called the degree of f. [For the zero polynomial, it’s convenient to denote deg=-∞. ] If deg(f)=n, we call the coefficient of xn the leading coefficient of f(x). If the leading coefficient is 1, we say the polynomial is monic.
Important: we should think of f(x) as a symbolic expression and not a function, for now, because there’re some dangers lurking underneath the functional interpretation of f.
 For starters, we have the following result:
For starters, we have the following result:
Theorem. The set of polynomials over R, denoted R[x], is a ring. The addition and product operations are the standard polynomial addition and product: let
and
; then
, where
;
, where
.
The unity 1 is just, well, 1 (i.e. 1 + 0x + 0x2 + … ). The proof is easy but a bit tedious, so we’re leaving it to the reader as an exercise. Note that R[x] is a commutative ring if and only if R is commutative.
The first danger of the day is that deg(fg) ≠ deg(f)deg(g) if R has zero-divisors. Indeed, if deg(f)=m and deg(g)=n, then the coefficient of xm+n is ambn which can be zero even if am and bn are not.
Proposition. If R has no non-zero zero-divisors, then deg(fg) = deg(f) + deg(g) for any polynomials f, g.
Our next definition is a natural extension from the case of real polynomials.
Definition. The derivative of f(x), denoted
or just f'(x), is given by:

Once again, the derivatives are formal derivatives, in the sense that we’re not thinking in terms of calculus and limits. Our derivative is merely a function which takes a polynomial and outputs another. The usual properties regarding derivatives of sums and products still hold.
;
;
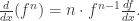
Do take note of the order of multiplication in the product law since the ring may well be non-commutative. Once again, the proof is left to the reader, but we’ll leave a hint to make his/her job easier. For the product law, note that the maps


are both bilinear in f and g. In other words, if we fix f (resp. g), then the resulting map is linear in g (resp. f). This reduces to the case of monomials 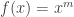

Now, the next bombshell is: 


E.g. let R = Z/3 which is a finite field. Then the polynomial 
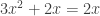
In general, we merely have 
 Polynomials as Functions
Polynomials as Functions

Any student of elementary algebra knows that we can substitute values in x to evaluate a polynomial. This holds for ![f(x) \in R[x]](https://s0.wp.com/latex.php?latex=f%28x%29+%5Cin+R%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Problem 1: product is not preserved if R is non-commutative.
We prefer not to do it when R is not commutative, because if we substitute x=r, then it’s not true in general that (fg)(r) = f(r)g(r).
E.g. consider the quaternion ring H. Suppose f(x) = ix and g(x) = jx. Then fg = (ij)x2 = kx2. This gives:
f(i) = -1, g(i) = –k but (fg)(i) = –k ≠ f(i)g(i).
The problem occurs because x=r does not commute with the coefficients of f(x), so we won’t attempt to interpret f as a function when the coefficients don’t commute.
Problem 2 : a non-zero polynomial can be a zero function.
This is best given by the example of R = Z/3. Take the polynomial f(x) = x3–x. The only elements of R are {0, 1, 2} mod 3, and all these satisfy f(0) = f(1) = f(2) = 0. More generally, if p is a prime, then the polynomial f(x) = xp–x over the ring Z/p becomes the zero function by Fermat’s little theorem.
With those caveats out of the way, let’s state the main theorem of this section.
Theorem. Let R be a commutative ring. The evaluation map gives a ring homomorphism:
where Func(R, R) is the set of functions R → R with addition and product given by: for all
,
;
.
The unity 1 is the constant function which takes all r to 1.
![R[x] \to \text{Func}(R, R), \ f(x) \mapsto (r \mapsto f(r)),](https://s0.wp.com/latex.php?latex=R%5Bx%5D+%5Cto+%5Ctext%7BFunc%7D%28R%2C+R%29%2C+%5C+f%28x%29+%5Cmapsto+%28r+%5Cmapsto+f%28r%29%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
We’ve already seen that the evaluation map is not injective in general. Clearly, it’s also far from surjective.
Remainder Theorem
Throughout this section, let’s assume R is commutative.
Theorem. Let
, where g(x) is monic (recall: this means leading coeff = 1). Then we can write:
,
for some
such that deg(r) < deg(g) (this includes g=0, whose degree is -∞).
Furthermore, q(x) and r(x) are unique, and we them the quotient and remainder of f(x) ÷ g(x) respectively.
We’ll sketch the proof: which is almost identical to the case of secondary school algebra.
- Case 1: deg(f) < deg(g). The only possibility is q(x)=0, r(x)=f(x), because if q≠0, then deg(gq) = deg(g)+deg(q) ≥ deg(g) > deg(r) (important: the first equality holds because g is monic!) which gives deg(f) = deg(gq+r) = deg(gq). But deg(gq) ≥ deg(g) so this contradicts the case assumption.
- Case 2: deg(f) ≥ deg(g). Let
, where n = deg(f). Show that the leading coefficient of q(x) must be
, where m = deg(g). Then apply induction on deg(f).
In particular, suppose g(x) = x – c for some c in R. Then f(x) = q(x)(x – c) + r, where r is a constant. Substitute x=c to obtain f(c) = r, so we have:
Remainder Theorem. If
and
, then we have:
,
for some
. As a corollary, we get the Factor Theorem : if f(c) = 0, then f(x) = (x-c)q(x) for some polynomial q(x).
[ An element c of R is called a root of f(x) if f(c) = 0. ]
Here’s another way of looking at it. Fixing c, we get a surjective ring homomorphism R[x] → R which takes f(x) → f(c). Then the factor theorem says the kernel of this map is precisely <x–c>.
Example 1
Consider the ring R[x, y, z] of all polynomials with real coefficients in x, y, z. This is (canonically isomorphic to) the ring of polynomials R[z], where R = R[x, y]. Now let (a, b, c) be an ordered triplet of real numbers.
- The remainder theorem for R = R[x, y] gives us f(x, y, z) = (z–c)q(x, y, z) + r(x, y).
- Applying remainder theorem to R = R[x] gives us r(x, y) = (y–b)q2(x, y) + r2(x).
- Finally, applying it to R = R gives r2(x) = (x–a)q3(x) + r3.
In conclusion:
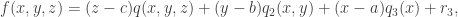
and upon substituting x=a, y=b, z=c, we get r3 = f(a, b, c). In short, the ring homomorphism R[x, y, z] → R which takes f(x, y, z) to a real number by evaluating it at (a, b, c) has ideal I = <x–a, y–b, z–c>. Since the quotient R[x, y, z]/I is isomorphic to R by the first isomorphism theorem, I is maximal.
Example 2
Suppose R is an integral domain and 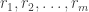
Indeed, since 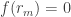
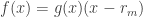

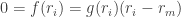

If R has zero-divisors, things can go very wrong. E.g. in R × R, the innocuous looking quadratic equation x2=x has 4 solutions: (0, 0), (0, 1), (1, 0) and (1, 1).
Omake: Shamir’s Secret Sharing Scheme
Polynomials in abstract ring theory are a key ingredient in Shamir’s secret sharing protocol. The problem is as follows: you have a secret code (e.g. 5-digit number) to a safe containing some highly sensitive documents. You’d like to distribute the code among 10 scientists so that:
- any 3 scientists can cooperate and obtain the code, but
- if any 2 scientists cooperate, they get absolutely no information on the code.
The second factor is critical: not only do the 2 scientists not know the full code, but the amount of knowledge they have pertaining to the code is zilch! In short, cutting up the code into binary bits and distributing them is out of the question, since each scientists would then know something about the code (each bit cuts the number of possibilities by half).
Shamir’s ingenious solution is as follows: pick a reasonably large prime p and take the finite field R = Z/p. Now:
- The computer randomly picks a polynomial
such that f(0) = c = secret code. The case of a=0 is not excluded.
- For i = 1, 2, …, 10, the computer then calculates f(i) and sends it to scientist #i.
- If any three scientists cooperate, they would have f(i), f(j), f(k) for three distinct positive integers i, j, k, and we know that every quadratic equation is uniquely determined by 3 points.
- If two scientists cooperate to get f(i) and f(j), the amount of information they have on the code is still zilch since for every value of f(0), there is a unique solution for f.

Step 3 can be performed by the Lagrange interpolation formula if one so desires: to interpolate (i, f(i)), (j, f(j)) and (k, f(k)), compute:

which is well-defined if i, j and k are distinct. Or we can solve simultaneous equations: e.g. to solve for f(1) = 2, f(2) = 3, f(3) = 9 for mod p=11, we have:

so the secret code is 6.
In the general case, say, you wish to design a secret sharing system whereby any (n+1) scientists can collaborate to obtain the code, and any n scientists cannot figure out anything about the code. To that end, a polynomial of degree n is required. Once again, Lagrange’s interpolation formula allows us to recover the entire polynomial given (n+1) distinct points, and hence the secret code.
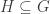 is a subgroup.
is a subgroup.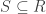 is a subring.
is a subring.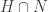 is a normal subgroup of H.
is a normal subgroup of H.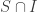 is an ideal of S.
is an ideal of S. is a normal subgroup, then HN is a subgroup of G
is a normal subgroup, then HN is a subgroup of G is an ideal, then I+S is a subring of R.
is an ideal, then I+S is a subring of R.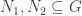 are normal subgroups, then so is
are normal subgroups, then so is 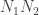 .
. are ideals, then so is
are ideals, then so is 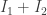 .
.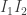 .
. is a subgroup, then so is
is a subgroup, then so is 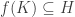 .
. is a subring, then so is
is a subring, then so is  .
. is a subgroup, then so is
is a subgroup, then so is  .
.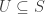 is a subring, then so is
is a subring, then so is  .
. is a normal subgroup, then so is
is a normal subgroup, then so is 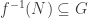 .
. is an ideal, then so is
is an ideal, then so is  .
. as groups.
as groups. as rings.
as rings.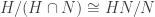 .
. .
. , where N and H are normal subgroups of G. Then
, where N and H are normal subgroups of G. Then  .
.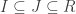 , where I and J are ideals of R. Then
, where I and J are ideals of R. Then  .
.
 on the LHS if and only if
on the LHS if and only if  on the RHS. The same holds for the ideals.
on the RHS. The same holds for the ideals.
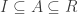 is an ideal or subring of R, let the corresponding element on the RHS be A/I. If A is an ideal (resp. subring) of R, then A/I is an ideal (resp. subring) of R/I.
is an ideal or subring of R, let the corresponding element on the RHS be A/I. If A is an ideal (resp. subring) of R, then A/I is an ideal (resp. subring) of R/I. is a subring or ideal, then let the corresponding A on the LHS be
is a subring or ideal, then let the corresponding A on the LHS be  . Prove that A contains I and A/I = B. Now fill up the proof by showing that by composing these two arrows in either order, we get the identity map on either the LHS or RHS. ♦
. Prove that A contains I and A/I = B. Now fill up the proof by showing that by composing these two arrows in either order, we get the identity map on either the LHS or RHS. ♦ on the LHS, indexed by i. Each ideal then corresponds to
on the LHS, indexed by i. Each ideal then corresponds to  on the RHS.
on the RHS.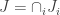 is the largest ideal (containing I) such that
is the largest ideal (containing I) such that 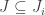 for each i. Translating it to the RHS, the corresponding J/I is also the largest ideal which contained in all
for each i. Translating it to the RHS, the corresponding J/I is also the largest ideal which contained in all 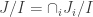 . This is yet another example of a “
. This is yet another example of a “ .
. , their intersection may not contain I).
, their intersection may not contain I). which corresponds to <4> ∩ <6> = <2> on the RHS.
which corresponds to <4> ∩ <6> = <2> on the RHS.![f^{-1}(\mathbf{R}) = \mathbf{R} + \left<y\right> \subset \mathbf{R}[x,y]](https://s0.wp.com/latex.php?latex=f%5E%7B-1%7D%28%5Cmathbf%7BR%7D%29+%3D+%5Cmathbf%7BR%7D+%2B+%5Cleft%3Cy%5Cright%3E+%5Csubset+%5Cmathbf%7BR%7D%5Bx%2Cy%5D&bg=ffffff&fg=333333&s=0&c=20201002) , which has basis given by 1, together with xmyn, where m ≥ 0 and n > 0.
, which has basis given by 1, together with xmyn, where m ≥ 0 and n > 0. . Then <x> is an ideal which is non-zero, hence <x>=R. This implies 1 is contained in <x>, so there exists an element y in R such that xy = 1. ♦
. Then <x> is an ideal which is non-zero, hence <x>=R. This implies 1 is contained in <x>, so there exists an element y in R such that xy = 1. ♦
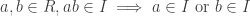 . We call such an I a prime ideal.
. We call such an I a prime ideal. , i.e. no ideal is strictly contained between I and R. We call such an I a maximal ideal.
, i.e. no ideal is strictly contained between I and R. We call such an I a maximal ideal.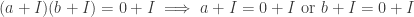 .
. .
. are J=I or J=R. ♦
are J=I or J=R. ♦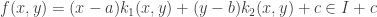 for some real c. Hence R[x, y]/I is isomorphic to R and I is maximal.
for some real c. Hence R[x, y]/I is isomorphic to R and I is maximal.
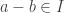 . Since I is an additive subgroup, we see that this is an equivalence relation. Further:
. Since I is an additive subgroup, we see that this is an equivalence relation. Further: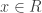 which maps to (0, 1), i.e. x ≡ 0 (mod I) and y ≡ 1 (mod J). By the same token, we get y such that y ≡ 1 (mod I) and y ≡ 0 (mod J). But now look at x+y. We have x+y ≡ 1 (mod I) and (mod J), so x+y ≡ 1 (mod I∩J). Since I∩J = {0}, x+y=1.
which maps to (0, 1), i.e. x ≡ 0 (mod I) and y ≡ 1 (mod J). By the same token, we get y such that y ≡ 1 (mod I) and y ≡ 0 (mod J). But now look at x+y. We have x+y ≡ 1 (mod I) and (mod J), so x+y ≡ 1 (mod I∩J). Since I∩J = {0}, x+y=1.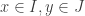 , x+y = 1. Taking this expression mod I and J, we get x ≡ 1 (mod J) and y ≡ 1 (mod I). In a nutshell:
, x+y = 1. Taking this expression mod I and J, we get x ≡ 1 (mod J) and y ≡ 1 (mod I). In a nutshell:
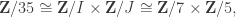
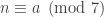 ,
,  : just take n = ay+bx = 15a + 21b.
: just take n = ay+bx = 15a + 21b. . Hence, the kernel of this map, S ∩ I, is an ideal of S and we get an injection S/(S ∩ I) → R/I.
. Hence, the kernel of this map, S ∩ I, is an ideal of S and we get an injection S/(S ∩ I) → R/I. , where I, R and S are explicitly defined. An easy way to do this is via constructing an epimorphism R → S with kernel I and letting the first isomorphism theorem do its job. Here’s a concrete example.
, where I, R and S are explicitly defined. An easy way to do this is via constructing an epimorphism R → S with kernel I and letting the first isomorphism theorem do its job. Here’s a concrete example. . Map f : U → R×R by taking the two diagonal entries a, b to the ordered pair (a, b). Then f is an epimorphism so we get
. Map f : U → R×R by taking the two diagonal entries a, b to the ordered pair (a, b). Then f is an epimorphism so we get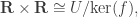
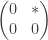 .
.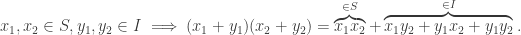
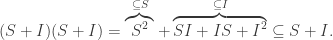
 , with
, with  .
.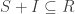 is a subring and
is a subring and 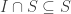 is an ideal of S. Then:
is an ideal of S. Then: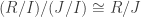 .
.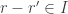 . So we need the condition:
. So we need the condition:
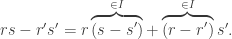
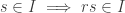 for each r in R. Likewise, in letting s = s’ and r’ = 0, we get
for each r in R. Likewise, in letting s = s’ and r’ = 0, we get 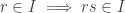 for each s in R. Clearly, these conditions suffice to ensure that the above hold.
for each s in R. Clearly, these conditions suffice to ensure that the above hold. . Note that if R is commutative, then rs=sr so it suffices to check for
. Note that if R is commutative, then rs=sr so it suffices to check for  .
.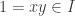 by definition of ideal. But this means for any r in R,
by definition of ideal. But this means for any r in R,  , i.e. I = R. This means a division ring has no non-trivial ideals. In particular, a field has no non-trivial ideal.
, i.e. I = R. This means a division ring has no non-trivial ideals. In particular, a field has no non-trivial ideal. , then the subset I of strictly upper-triangular real matrices
, then the subset I of strictly upper-triangular real matrices  is an ideal since
is an ideal since 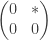
 and similarly
and similarly 
 =
=  . The ring quotient U/I is isomorphic to R × R by mapping the two diagonal entries (a and b) of a matrix to
. The ring quotient U/I is isomorphic to R × R by mapping the two diagonal entries (a and b) of a matrix to  .
.![\{2a(x) + x\cdot b(x) : a(x), b(x) \in \mathbf{Z}[x]\}](https://s0.wp.com/latex.php?latex=%5C%7B2a%28x%29+%2B+x%5Ccdot+b%28x%29+%3A+a%28x%29%2C+b%28x%29+%5Cin+%5Cmathbf%7BZ%7D%5Bx%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) is an ideal which is not of the above form.
is an ideal which is not of the above form.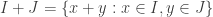 . This is an ideal of R. In fact, it is the “smallest ideal of R containing I and J“. [ This just means (i) it contains both I and J, and (ii) any ideal containing I and J must contain it. ]
. This is an ideal of R. In fact, it is the “smallest ideal of R containing I and J“. [ This just means (i) it contains both I and J, and (ii) any ideal containing I and J must contain it. ] . Then IJ is an ideal of R.
. Then IJ is an ideal of R. .
. . Since <X> is closed under addition, it must contain all finite sums of the form
. Since <X> is closed under addition, it must contain all finite sums of the form  , where
, where 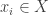 and
and 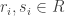 . On the other hand, the set of all such elements clearly satisfies the conditions of being an ideal. Thus:
. On the other hand, the set of all such elements clearly satisfies the conditions of being an ideal. Thus:
 any further. However, if R is commutative, then we only need to consider:
any further. However, if R is commutative, then we only need to consider: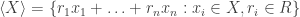
 . In particular,
. In particular, (for notational convenience, we set <x> := <{x}>) – such ideals are called principal ideals;
(for notational convenience, we set <x> := <{x}>) – such ideals are called principal ideals; ;
; ;
; ;
; .
. .
. forms a subring, and the set D of diagonal matrices forms a subring of U. [ Note that D is isomorphic to R × R, under component-wise addition and multiplication. We haven’t defined isomorphism, but you
forms a subring, and the set D of diagonal matrices forms a subring of U. [ Note that D is isomorphic to R × R, under component-wise addition and multiplication. We haven’t defined isomorphism, but you  .
. ,
,  . On the other hand, the set of such numbers clearly forms a subring, so S = set of all numbers of the form
. On the other hand, the set of such numbers clearly forms a subring, so S = set of all numbers of the form  . Furthermore, it is known that π is
. Furthermore, it is known that π is  . Now it’s clear that the resulting subring is R[x2].
. Now it’s clear that the resulting subring is R[x2]. .
. .
. . Also,
. Also,  .
. .
. , then we call the ring an integral domain (or just domain if we’re lazy).
, then we call the ring an integral domain (or just domain if we’re lazy). =
=  =
=  .
. , where i, j, k satisfy the multiplication laws
, where i, j, k satisfy the multiplication laws  and ij = –ji = k, jk = –kj = i, ki = –ik = j. Then H is a non-commutative division ring – if you’re not familiar with quaternions, just take it as it is for now.
and ij = –ji = k, jk = –kj = i, ki = –ik = j. Then H is a non-commutative division ring – if you’re not familiar with quaternions, just take it as it is for now.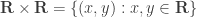 of ordered pairs of real numbers is a ring under component-wise addition and multiplication. This is not an integral domain since (1, 0) × (0, 1) = (0, 0).
of ordered pairs of real numbers is a ring under component-wise addition and multiplication. This is not an integral domain since (1, 0) × (0, 1) = (0, 0). , so since c is not a zero-divisor we have a=b. In particular, cancellation always works in an integral domain.
, so since c is not a zero-divisor we have a=b. In particular, cancellation always works in an integral domain.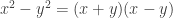 only hold in commutative rings. That includes our favourite binomial formula as well, for if the ring is non-commutative, then we’re forced to write:
only hold in commutative rings. That includes our favourite binomial formula as well, for if the ring is non-commutative, then we’re forced to write:
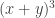 would have 8 terms.
would have 8 terms.
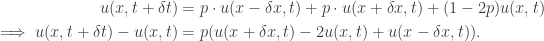
 (#)
(#)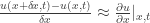 ,
, .
. .
.![\begin{array}{rl}u(x, y, t+\delta t) - u(x,y,t) &= p[u(x+\delta x,y,t)-2u(x,y,t)+u(x-\delta x,y,t)]\\ &+p[u(x,y+\delta y,t) - 2u(x,y,t) + u(x,y-\delta y,t)]\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brl%7Du%28x%2C+y%2C+t%2B%5Cdelta+t%29+-+u%28x%2Cy%2Ct%29+%26%3D+p%5Bu%28x%2B%5Cdelta+x%2Cy%2Ct%29-2u%28x%2Cy%2Ct%29%2Bu%28x-%5Cdelta+x%2Cy%2Ct%29%5D%5C%5C+%26%2Bp%5Bu%28x%2Cy%2B%5Cdelta+y%2Ct%29+-+2u%28x%2Cy%2Ct%29+%2B+u%28x%2Cy-%5Cdelta+y%2Ct%29%5D%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 ;
; .
.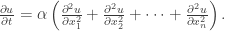
 by the symbol Δ or the “nabla-squared” symbol
by the symbol Δ or the “nabla-squared” symbol  . We’ll also call it the Laplacian operator. This gives an alternate way of writing the heat equation:
. We’ll also call it the Laplacian operator. This gives an alternate way of writing the heat equation:
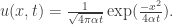

 . This completely matches the discrete case of the drunken man (whose variance was 2pt)! The heat kernel also exists for the higher-dimensional case, but we need to replace x2 by ∑ixi2 in the formula for u.
. This completely matches the discrete case of the drunken man (whose variance was 2pt)! The heat kernel also exists for the higher-dimensional case, but we need to replace x2 by ∑ixi2 in the formula for u.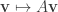 . Now dot-product of two column vectors can be written via the matrix notation
. Now dot-product of two column vectors can be written via the matrix notation  , since the transpose changes a column vector into a row. Thus, A preserves the inner product if and only if:
, since the transpose changes a column vector into a row. Thus, A preserves the inner product if and only if: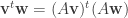
 and the two sides are equal iff
and the two sides are equal iff 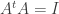 .
.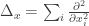 is coordinate-independent. The subscript x was added to highlight the fact that Δ was defined in terms of coordinate (xi).
is coordinate-independent. The subscript x was added to highlight the fact that Δ was defined in terms of coordinate (xi).
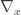 is the column vector of differential operators comprising of
is the column vector of differential operators comprising of 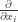 . [ This differential operator takes a scalar function f to the vector comprising of its partial derivatives. ]
. [ This differential operator takes a scalar function f to the vector comprising of its partial derivatives. ]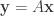 for some orthogonal matrix A. The corresponding transformation is given by:
for some orthogonal matrix A. The corresponding transformation is given by: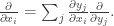
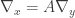 . Now the Laplacian operator gives:
. Now the Laplacian operator gives:
 , the outcome would have been coordinate-dependent.
, the outcome would have been coordinate-dependent.
 since the man must be found somewhere.
since the man must be found somewhere.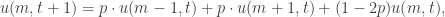 (*)
(*)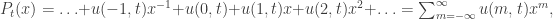
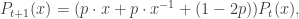
 . This expression has certain advantages in computation:
. This expression has certain advantages in computation: . But we already know this since Pt(1) represents the sum of all u(m, t) across m, i.e. it equals 1.
. But we already know this since Pt(1) represents the sum of all u(m, t) across m, i.e. it equals 1.
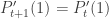 . Since
. Since 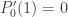 , we also have
, we also have  for all t. Again, we already know this since
for all t. Again, we already know this since  represents the expected position of our friend, which is always 0 since he’s just as inclined to go left as he is to go right. In probability notation, we have
represents the expected position of our friend, which is always 0 since he’s just as inclined to go left as he is to go right. In probability notation, we have  , where Xt is the random variable for our friend’s location at time t.
, where Xt is the random variable for our friend’s location at time t.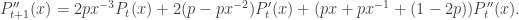
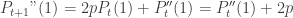 . Since
. Since  we have
we have  . But
. But
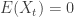 we can calculate the variance via
we can calculate the variance via
 at time t?
at time t?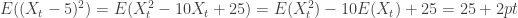 .
.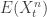 for various n. In fact, since
for various n. In fact, since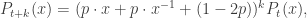
 for m>0 (u(m, 0) = 0 if m ≤ 0),
for m>0 (u(m, 0) = 0 if m ≤ 0), which diverges since it is the renowned
which diverges since it is the renowned 

 .
.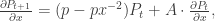

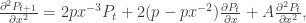
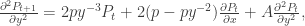

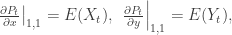

 , where each mi is an integer and ai‘s are distinct terms belonging to S. Thus:
, where each mi is an integer and ai‘s are distinct terms belonging to S. Thus: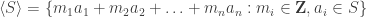 .
.

 (where
(where  ) to the element
) to the element 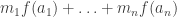 .
.
 . The direct sum is the subgroup:
. The direct sum is the subgroup:
 is precisely the set of all integer sequences; while the direct sum
is precisely the set of all integer sequences; while the direct sum  is the set of all integer sequences with only finitely many non-zero entries.
is the set of all integer sequences with only finitely many non-zero entries.
 . For every index i, there is a projection map
. For every index i, there is a projection map  which takes (xi)i to the i-th component xi. This gives us a whole bunch of maps pi. The gist of the matter is as follows.
which takes (xi)i to the i-th component xi. This gives us a whole bunch of maps pi. The gist of the matter is as follows.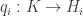 , there is a unique homomorphism
, there is a unique homomorphism 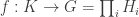 such that
such that  for every i.
for every i.
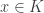 to the element
to the element  which is an element of
which is an element of 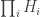 . The fact that f is a homomorphism follows from the fact that all the qi‘s are.
. The fact that f is a homomorphism follows from the fact that all the qi‘s are. . For each index i, we get an injection
. For each index i, we get an injection  which takes
which takes  to the element (…, 0, 0, …, 0, xi, 0, … ) in G’, i.e. all components are 0 except the i-th component, which takes the value of xi.
to the element (…, 0, 0, …, 0, xi, 0, … ) in G’, i.e. all components are 0 except the i-th component, which takes the value of xi. , there is a unique homomorphism
, there is a unique homomorphism  such that
such that  for each i.
for each i.
 is a multi-component
is a multi-component  , where all but finitely many xi‘s are zero. So we can let g take (xi) to
, where all but finitely many xi‘s are zero. So we can let g take (xi) to  . This is a well-defined sum since there’re only finitely many non-zero terms (we don’t know how to sum infinitely many terms without some form of convergence).
. This is a well-defined sum since there’re only finitely many non-zero terms (we don’t know how to sum infinitely many terms without some form of convergence).