
1-Dimensional Heat Equation
Consider the case of 1-dimensional random walk. The equation (*) from the previous post gives:

for t≥0. Suppose the intervals between successive time/space points are variable. Let’s rewrite it in the following form:
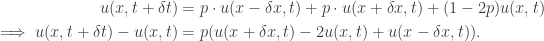
Setting δt ≈ ε2 and δx ≈ ε, we divide both sides by ε2 to obtain:

From the approximation,
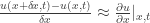
we see that the RHS of (#) approximates with 
Definition. The 1-dimensional heat equation is the following partial differential equation (for some parameter α):
.
This makes sense if we consider the kinetic theory of particles. Assume that we have a bunch of particles placed at equal intervals along a line. Heat of a particle refers to the amount of energy it possesses. At each time interval, the heat may transmit to a neighbouring particle (either to the left or right) or it may remain with the current particle. Since u(x, t) plots the amount of heat at each spacetime point, the random walk model is a reasonable approximation, whose limit gives us the heat equation.

Higher Dimensional Heat Equation
Let’s consider the two-dimensional case. We get the recurrence relation in time:
u(x, y, t+1) = p(u(x-1, y, t) + u(x+1, y, t) + u(x, y-1, t) + u(x, y+1, t)) + (1-4p)u(x, y, t).
Let’s re-express the above as follows, using arbitrary space and time interval lengths:
![\begin{array}{rl}u(x, y, t+\delta t) - u(x,y,t) &= p[u(x+\delta x,y,t)-2u(x,y,t)+u(x-\delta x,y,t)]\\ &+p[u(x,y+\delta y,t) - 2u(x,y,t) + u(x,y-\delta y,t)]\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brl%7Du%28x%2C+y%2C+t%2B%5Cdelta+t%29+-+u%28x%2Cy%2Ct%29+%26%3D+p%5Bu%28x%2B%5Cdelta+x%2Cy%2Ct%29-2u%28x%2Cy%2Ct%29%2Bu%28x-%5Cdelta+x%2Cy%2Ct%29%5D%5C%5C+%26%2Bp%5Bu%28x%2Cy%2B%5Cdelta+y%2Ct%29+-+2u%28x%2Cy%2Ct%29+%2B+u%28x%2Cy-%5Cdelta+y%2Ct%29%5D%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
As before, if we set δt ≈ ε2 and δx = δy ≈ ε then divide both sides by ε2, we get:
- LHS
;
- RHS
.
Thus, let’s define the higher-dimensional heat equation as follows: if we have orthogonal coordinates x1, x2, …, xn, then the n-dimensional heat equation is given by (for some parameter α):
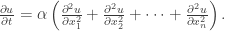
For convenience, we’ll denote the RHS operation 


Heat Kernel
The heat equation is usually given together with boundary conditions, e.g. the value of u(x, t) for t=0. This is completely analogous with our random walk, which starts with some probability distribution at t=0, then proceed at incremental discrete time steps. Another possibility is to start from t=0, and bound the system in space (e.g. x2 + y2 + z2 ≤ r2) and specify the heat distribution at the space boundary as well (e.g. x2 + y2 + z2 = r2).
Suppose, during t=0, the heat is all localised at the point x=0. This corresponds to the discrete case where our drunken friend starts at the point m=0. The function in this case is given by the Dirac delta function, δ(x), which unfortunately is not a function at all. Formally, δ(0)=”∞” and δ(x)=0 at x≠0, such that the integral ∫R δ(x)dx = 1. This might seem baffling to mathematicians, but physicists have no qualms using it all the time. It’s possible to formally justify the δ(x) notation via the language of distributions, but that’s another story for another day.
Anyway, the solution (called the heat kernel) for this particular case is really nice. In the 1-D case, this is:
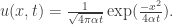
We’ll leave it to the reader to check that this equation satisfies the 1-D heat equation. Graphically, for α=1, this gives the plots:
 Notice that the probability distribution is a Gaussian (normal) curve which gradually spreads out as t increases. Also, the variance
Notice that the probability distribution is a Gaussian (normal) curve which gradually spreads out as t increases. Also, the variance 
In a nutshell, the heat kernel is the continuous variant of the probability distribution function for the drunken man problem.
However, there is an important distinction: for the discrete case the probability parameter cannot exceed 1/2, but for the PDE case, the parameter α can be any positive real number.
Independence of Coordinates
One important test to see if an equation makes “physical sense” is to check if it’s preserved under a change in coordinates. For example, vectors should be changed according to the coordinate transformation, while scalars should remain unchanged.
In n-dimensional space, transformation of a column vector corresponds to left multiplication by a fixed matrix A, i.e. 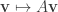

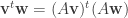
for all vectors v and w. Since (AB)t = BtAt, the RHS simplifies to: 
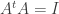
Definition. An n × n real matrix A is said to be orthogonal if
Now, let’s check that the heat equation is independent of our choice of coordinates. To do so, it suffices to check that the Laplacian operator 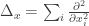
First, we write this operator as:

where 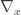
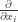
Now suppose we have a different choice of coordinates which results in a transformation: 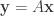
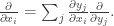
Written in terms of the differential operator, we have: 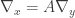

so the Laplacian is the same in both coordinates (xi) and (yi).
Conclusion. The heat equation is coordinate-independent, even though we had obtained it as a continuous variant of the drunken man problem which had explicitly chosen coordinates.
The above verification is non-trivial: e.g. if we had used the operator 
In higher physics, you’ll learn that one often obtains an equation simply because it’s the simplest one which “makes physical sense”, but that’d be another story for another day.
