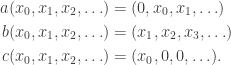Previously, we defined continuous limits and proved some basic properties. Here, we’ll try to port over more results from the case of limits of sequences.
Monotone Convergence Theorem. If f(x) is increasing on the open interval (c, a) and has an upper bound, then
exists.
[ Recall that by “increasing”, we mean: if x ≤ y, then f(x) ≤ f(y). In particular, even a constant function is considered “increasing” under our definition. ]

Proof.
As before let L = sup{f(x) : c < x < a}, which is finite since f(x) has an upper bound. For each ε>0, since L-ε is not an upper bound, there exists δ>0 such that L-ε < f(a-δ) ≤ L. Hence, for any a-δ < x < a, we also have f(x) ≥ f(a-δ) > L-ε and f(a-δ) ≤ L. ♦
Note that this theorem has many variations. For example, f(x) can be either monotonically increasing or decreasing. Or the limit can be either left or right. Here’re two possibilities:
- If f(x) is decreasing on (a, b) and has an upper bound, then
exists.
- If f(x) is increasing on (-∞, b) and has a lower bound, then
exists.

Example
Define 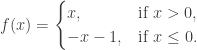

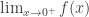

 Next, we have the following.
Next, we have the following.
Squeeze Theorem. Suppose
on the open interval (c, a). If
then
as well. This holds for the limits
and
as well.

Proof.
We’ll only prove the case for left limits. Let ε>0. Then there exist positive δ1 and δ2 such that:
- whenever a-δ1 < x < a, we have |g(x) – L| < ε;
- whenever a-δ2 < x < a, we have |h(x) – L| < ε.
Hence if δ = min(δ1, δ2), then whenever a-δ < x < a, we have f(x) ≤ h(x) < L+ε and f(x) ≥ g(x) > L-ε. Thus |f(x) – L| < ε. ♦
Example
Consider the function 

Since 


(Graphs plotted by wolframalpha.com)
Continuous Functions: Basic Concepts
We wish to define what it means for a function to be continuous at x=a. It’s natural to define it in terms of limits.
Definition. Suppose f(x) is defined on an open interval (b, c) containing a. We say that f is continuous at a, if
.
Equivalently, we say that f is continuous at a, if for every ε>0, there exists δ>0, such that:

Example
For example, let’s consider 
Since 
The second definition is really neat, because now even if f(x) is not defined on an open interval about a, we can talk about continuity at a itself. To be explicit, suppose D is a subset of the reals R, and f : D → R is a function. If a lies in D, we say that f(x) is continuous at x=a if:
- for every ε>0, there exists δ>0, such that whenever |x–a|<δ and x lies in D, we have |f(x)-f(a)|<ε.
Example
Consider the function 

 Strange as it may sound, f(x) is continuous at x=0 according to our definition. Indeed, let’s check the definition. When someone throws an ε>0 at us, we have to produce a δ>0, such that if |x-0| = |x| < δ and x lies in D, then |f(x)-f(0)| = |f(x)-0.5| < ε. What can this δ be? It’s clear that δ=0.5 works for any ε(!), for the condition “|x| < 0.5 and x lies in D” is satisfied by one and only one point: namely, x=0, in which case |f(x)-f(0)|=0.
Strange as it may sound, f(x) is continuous at x=0 according to our definition. Indeed, let’s check the definition. When someone throws an ε>0 at us, we have to produce a δ>0, such that if |x-0| = |x| < δ and x lies in D, then |f(x)-f(0)| = |f(x)-0.5| < ε. What can this δ be? It’s clear that δ=0.5 works for any ε(!), for the condition “|x| < 0.5 and x lies in D” is satisfied by one and only one point: namely, x=0, in which case |f(x)-f(0)|=0.
It’s also clear from the proof that we’re at complete liberty to shift f(0) to any point we wish and the function is still continuous. This occurs due to an anomaly in the domain of definition D. As the point x=0 is too far from its neighbours, f(0) can take whatever the heck it wants without breaking continuity.
So when is f(a) uniquely determined by continuity?
Definition. Let D be a subset of R. A real number a is called a point of accumulation (or cluster point, or limit point) if for every ε>0, there exists
such that |x-a|<ε.
In short a is a point of accumulation if there are points of D which are arbitrarily close to it. E.g. in the above example 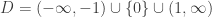
The result we wish to prove is the following.
Definition. Let D be a subset of R and a be point of accumulation of D. If two functions
agree on D-{a} and are continuous at a, then f(a) = g(a).
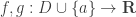
Proof.
If not, let ε = |f(a)-g(a)|/2. Then there exist positive δ1 and δ2 such that:
;
.
Since a is a point of accumulation, we can pick an x in D such that 0 < |x–a| < min(δ1, δ2). This x satisfies f(x)=g(x) by condition, thus giving:
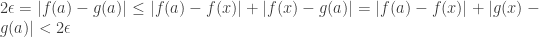
which is absurd. ♦
Further Properties
As the reader may suspect, we also have the following properties: if 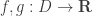
- f+g : D → R is continuous at a;
- fg : D → R is continuous at a;
- if f(a)≠0, then 1/f : D’ → R is continuous at a, where D’ is the set of x in D for which f(x)≠0.
The proof is extremely similar to the case of limits, so we’ll skip it for now. The conscientious reader may want to prove the above results to convince himself/herself, but we’ll prove them as a corollary in the next article by looking at higher-dimensional continuity.
As a consequence, since constant functions f(x)=c and the identity function f(x)=x are both continuous at every point in R, so is any polynomial function.
Exercises
- Prove that if a is not a point of accumulation of D, then any function
is automatically continuous at a.
- Prove that if f : (c, a] → R is a function, where (c, a] is the set of x, c < x ≤ a, then f is continuous at a if and only if
.
- Let f : D → R be a function. Prove that f(x) is continuous at a if and only if for every sequence (xn) in D which converges to a, the sequence f(xn) also converges to f(a).
[ Answer for 3 (highlight to read). (1) Suppose LHS holds and (xn) → a. For any ε>0, pick δ>0 such that when |x–a|<δ and x in D, |f(x)-f(a)|<ε. Now pick N such that when n>N, we have |xn–a|<δ. Hence when n>N, |f(xn)-f(a)|<ε. (2) Suppose f is not continuous at a. Take the negation of the definition of continuity: there exists ε>0 such that for any δ>0, we can find x in D, such that |x–a|<δ but |f(x)-f(a)|≥ε. Let δ=1/n, for n=1,2,3,… and pick xn such that |xn–a|<1/n but |f(x)-f(a)|≥ε. Prove that (xn) → a but f(xn) doesn’t converge to f(a). ]
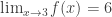 . First, we define a punctured neighbourhood of a real number a to be a set of the form: (a-ε, a+ε) – {a}, i.e. the set
. First, we define a punctured neighbourhood of a real number a to be a set of the form: (a-ε, a+ε) – {a}, i.e. the set  for some positive ε.
for some positive ε.
 if:
if:
 and
and  ,
, , defined on x≠2. Prove that
, defined on x≠2. Prove that  .
. . ♦
. ♦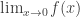 does not exist.
does not exist.
 and
and  . Then:
. Then: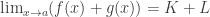 ;
; ;
; ;
;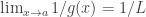 .
.

 for any real c;
for any real c; ;
;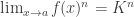 for n=1, 2, … ; if K≠0, this even holds for all integers n;
for n=1, 2, … ; if K≠0, this even holds for all integers n; .
.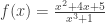 , then
, then  .
. , which can be easily proven from ε-δ definition. Now, apply the above properties successively:
, which can be easily proven from ε-δ definition. Now, apply the above properties successively:  ,
,  … . ♦
… . ♦ if:
if: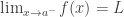 if:
if: ;
; , so there’s a need to talk about a limit “approaching infinity”. Then there’s the case where x itself can approach +∞ or -∞. All these cases multiply to a huge number of possibilities! We can summarise by saying:
, so there’s a need to talk about a limit “approaching infinity”. Then there’s the case where x itself can approach +∞ or -∞. All these cases multiply to a huge number of possibilities! We can summarise by saying: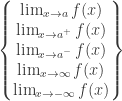 =
= ![\left[\begin{matrix} L \\ \infty\\-\infty\end{matrix}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bmatrix%7D+L+%5C%5C+%5Cinfty%5C%5C-%5Cinfty%5Cend%7Bmatrix%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) if for every
if for every ![\left[\begin{matrix} \epsilon>0 \\ N \\ N\end{matrix}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bmatrix%7D+%5Cepsilon%3E0+%5C%5C+N+%5C%5C+N%5Cend%7Bmatrix%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) there exists
there exists  such that
such that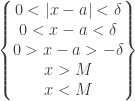 , we have
, we have ![\left[\begin{matrix} |f(x)-L|<\epsilon\\ f(x)>N \\ f(x)<N\end{matrix}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bmatrix%7D+%7Cf%28x%29-L%7C%3C%5Cepsilon%5C%5C+f%28x%29%3EN+%5C%5C+f%28x%29%3CN%5Cend%7Bmatrix%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. . We call this sum an infinite series. Let
. We call this sum an infinite series. Let  be the partial sums of the series.
be the partial sums of the series.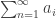 is L (resp. ∞, -∞) if the partial sums
is L (resp. ∞, -∞) if the partial sums 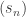 converge to L (resp. ∞, -∞). The series is said to be convergent if the sum is a real number L.
converge to L (resp. ∞, -∞). The series is said to be convergent if the sum is a real number L.

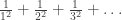
 , so upon dropping the first term (1), we can apply squeeze theorem on the partial sums to obtain:
, so upon dropping the first term (1), we can apply squeeze theorem on the partial sums to obtain:
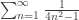 . We can write the sum in two different ways:
. We can write the sum in two different ways: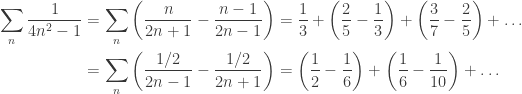
 which approaches 1/2. Hence, the series converges to 1/2, which is also obvious from the second sum.
which approaches 1/2. Hence, the series converges to 1/2, which is also obvious from the second sum. is convergent, then
is convergent, then  .
.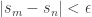 for all m, n > N. In particular,
for all m, n > N. In particular,  for all n > N+1. Hence,
for all n > N+1. Hence,  which converge to 0, but whose sums don’t converge. The most famous example is that of the
which converge to 0, but whose sums don’t converge. The most famous example is that of the  , where the sum of the first n terms is approximately log(n).
, where the sum of the first n terms is approximately log(n). and
and 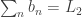 . Then:
. Then: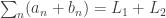 ;
; for any real c.
for any real c.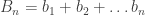 for the partial sums of bn, then:
for the partial sums of bn, then: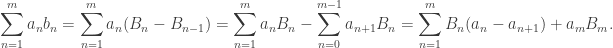
 converges.
converges.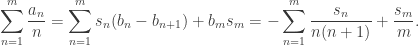
 . Hence it suffices to show that
. Hence it suffices to show that  converges. But since |sn|≤L are bounded, we have:
converges. But since |sn|≤L are bounded, we have:
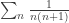 converges, its partial sums form a Cauchy sequence. This in turn implies that the partial sums of
converges, its partial sums form a Cauchy sequence. This in turn implies that the partial sums of 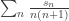 form a Cauchy sequence, and we’re done. ♦
form a Cauchy sequence, and we’re done. ♦ is convergent.
is convergent.
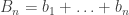 and thus |Bn| ≤ 2. Since
and thus |Bn| ≤ 2. Since  , we also have
, we also have 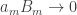 so it suffices to show that
so it suffices to show that 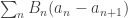 converges. Now,
converges. Now,
 . By the alternating series test, the series converges, though the test doesn’t give any hint what the sum might be.
. By the alternating series test, the series converges, though the test doesn’t give any hint what the sum might be. is a series, then we can permute the terms to obtain
is a series, then we can permute the terms to obtain  , where π:N → N is a bijective function. For example:
, where π:N → N is a bijective function. For example: , i.e. π(1) = 2, π(2) = 1, and π(m) = m for all m > 2;
, i.e. π(1) = 2, π(2) = 1, and π(m) = m for all m > 2;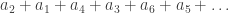 , i.e. π(2k-1) = 2k, π(2k) = 2k-1 for k=1, 2, 3, … .
, i.e. π(2k-1) = 2k, π(2k) = 2k-1 for k=1, 2, 3, … . is convergent. On the one hand, we can write:
is convergent. On the one hand, we can write: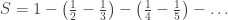
 , k = 1, 2, 3, … .
, k = 1, 2, 3, … . is said to converge absolutely if the series
is said to converge absolutely if the series 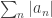 converges. If
converges. If  we saw above is only conditionally convergent. On the other hand, the alternating series
we saw above is only conditionally convergent. On the other hand, the alternating series  is absolutely convergent.
is absolutely convergent. for all n > m > N.
for all n > m > N.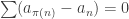 . To do that, let:
. To do that, let:

 as required. ♦
as required. ♦ .
.

 if for every
if for every  we eventually have
we eventually have 
 . Clearly
. Clearly  since we’re taking the sup of fewer elements as we go along. Since (bn) is a decreasing sequence, it must have a limit. The limit superior of (an), written
since we’re taking the sup of fewer elements as we go along. Since (bn) is a decreasing sequence, it must have a limit. The limit superior of (an), written 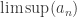 , is defined by
, is defined by  .
.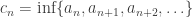 . Now
. Now 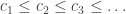 so it has a limit, which is the limit inferior of (an), written
so it has a limit, which is the limit inferior of (an), written  .
.
 . In this case, the limit superior is +∞.
. In this case, the limit superior is +∞.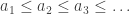 is an increasing sequence which converges to a finite L.Suppose an = (-1)n, i.e. the sequence is -1, +1, -1, +1, … . Then we have: for all n, bn = +1 and cn = -1. Thus, lim sup (an) = +1, lim inf (an) = -1.
is an increasing sequence which converges to a finite L.Suppose an = (-1)n, i.e. the sequence is -1, +1, -1, +1, … . Then we have: for all n, bn = +1 and cn = -1. Thus, lim sup (an) = +1, lim inf (an) = -1.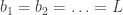 and lim sup (an) = L.
and lim sup (an) = L. if c > 0;
if c > 0; if c < 0;
if c < 0; . [ If you can’t recall which way the inequality goes, just think of the two alternating sequences (1, 0, 1, 0, 1, 0, …) and (0, 1, 0, 1, 0, 1, …). Then LHS = 1 and RHS = 1+1 = 2. ]
. [ If you can’t recall which way the inequality goes, just think of the two alternating sequences (1, 0, 1, 0, 1, 0, …) and (0, 1, 0, 1, 0, 1, …). Then LHS = 1 and RHS = 1+1 = 2. ]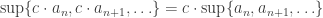 if c>0.
if c>0. if c<0.
if c<0. and
and  . Then for each m≥n,
. Then for each m≥n, 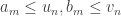 , and thus
, and thus  . Hence,
. Hence,  . Take the limit of both sides. ♦
. Take the limit of both sides. ♦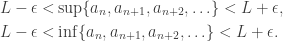
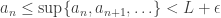 and
and  . Hence, eventually
. Hence, eventually  which proves that lim (an) = L. ♦
which proves that lim (an) = L. ♦ for all n. Now the theorem says: an increasing sequence with an upper bound is convergent.
for all n. Now the theorem says: an increasing sequence with an upper bound is convergent. ♦
♦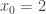 ,
,  . Prove that (xn) is convergent and find its limit.
. Prove that (xn) is convergent and find its limit. by induction. For n=0 this is obvious. Suppose we have
by induction. For n=0 this is obvious. Suppose we have  . For the next iteration, we have:
. For the next iteration, we have: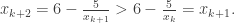
 which completes the induction. Next, note that
which completes the induction. Next, note that  since xn > 0. Hence, (xn) is an increasing sequence with an upper bound and must converge to some L.
since xn > 0. Hence, (xn) is an increasing sequence with an upper bound and must converge to some L. converges.
converges.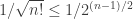 . But
. But 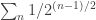 converges by sum of geometric series. Hence, an is an increasing sequence with an upper bound. By MCT, it converges. ♦
converges by sum of geometric series. Hence, an is an increasing sequence with an upper bound. By MCT, it converges. ♦ . So the sequence is Cauchy.
. So the sequence is Cauchy.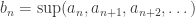 . Then
. Then 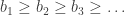 since bn takes the sup of more elements than bn+1. Since (an) has a lower bound so does (bn) and by MCT, (bn) converges to some L.
since bn takes the sup of more elements than bn+1. Since (an) has a lower bound so does (bn) and by MCT, (bn) converges to some L. so we can find n > N such that
so we can find n > N such that  . Yet
. Yet  , which gives
, which gives  .
. . ♦
. ♦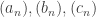 be three sequences with
be three sequences with  . Suppose an → L and cn → L. Then bn → L.
. Suppose an → L and cn → L. Then bn → L.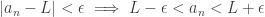 ;
; ;
; and
and 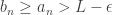 , i.e.
, i.e. 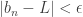 . ♦
. ♦ has a limit of 0.
has a limit of 0. . Since 2/n2 → 0, the result follows from the squeeze theorem. ♦
. Since 2/n2 → 0, the result follows from the squeeze theorem. ♦ , then bn → L.
, then bn → L.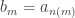 , for some increasing n(1) < n(2) < n(3) < …
, for some increasing n(1) < n(2) < n(3) < …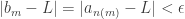 . Hence the subsequence (bm) also converges to L.
. Hence the subsequence (bm) also converges to L. such that x ≥ y for all
such that x ≥ y for all  .If S has an upper bound, we say it is upper bounded.
.If S has an upper bound, we say it is upper bounded. is an upper bound of S, we call it the maximum of S, denoted max(S).
is an upper bound of S, we call it the maximum of S, denoted max(S). is a lower bound of S, we call it the minimum of S, denoted min(S).
is a lower bound of S, we call it the minimum of S, denoted min(S).



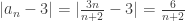 . Now, for any ε>0, we set N = 6/ε. Then:
. Now, for any ε>0, we set N = 6/ε. Then: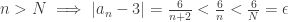 ,
,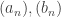 be sequences converging to K, L respectively. Then:
be sequences converging to K, L respectively. Then: converges to K+L;
converges to K+L; converges to KL;
converges to KL; converges to 1/L.
converges to 1/L.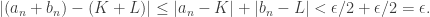
 , we pick ε=1, and by definition of convergence, there exists N such that when n > N, we have
, we pick ε=1, and by definition of convergence, there exists N such that when n > N, we have
 , just use:
, just use: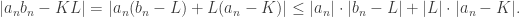
 . Given any ε>0, pick M, M’ such that:
. Given any ε>0, pick M, M’ such that: .
. , write:
, write: .
. and so
and so 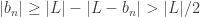 .
. , there exists M such that whenever n>M, we get
, there exists M such that whenever n>M, we get  . Now letting N = max{M, M’}, whenever n>N, we get:
. Now letting N = max{M, M’}, whenever n>N, we get: ♦
♦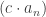 converges to cK;
converges to cK; converges to K-L;
converges to K-L;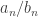 converges to K/L.
converges to K/L. . Use the fact that 1/n2 → 0 and we get an → 1/2. ♦
. Use the fact that 1/n2 → 0 and we get an → 1/2. ♦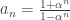 where α = 2011/2012. Since
where α = 2011/2012. Since  , an → 1. ♦
, an → 1. ♦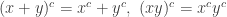 , for all
, for all ![x,y\in\mathbf{Z}[i].](https://s0.wp.com/latex.php?latex=x%2Cy%5Cin%5Cmathbf%7BZ%7D%5Bi%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
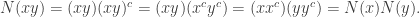
 , where
, where  .
.

 , where
, where  . Give a sample solution.
. Give a sample solution.
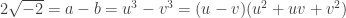 . Now we only need to take all factors of 2√-2 and solve. E.g.:
. Now we only need to take all factors of 2√-2 and solve. E.g.: . Solving them gives:
. Solving them gives: 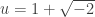 and
and  which are legit elements of Z[√-2]. This gives
which are legit elements of Z[√-2]. This gives 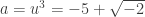 and
and 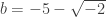 . So x=-5, y = uv = 3.
. So x=-5, y = uv = 3. for some integers m and n. The reader may check that Z[α] is an Euclidean ring for the following cases:
for some integers m and n. The reader may check that Z[α] is an Euclidean ring for the following cases: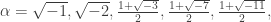

![q\in \mathbf{Z}[\alpha]](https://s0.wp.com/latex.php?latex=q%5Cin+%5Cmathbf%7BZ%7D%5B%5Calpha%5D&bg=ffffff&fg=333333&s=0&c=20201002) and s lies in ABCD. Since the four circles cover the parallelogram, it follows that we can pick s such that |s| < 1.
and s lies in ABCD. Since the four circles cover the parallelogram, it follows that we can pick s such that |s| < 1.![x,y\in \mathbf{Z}[\alpha], y\ne 0](https://s0.wp.com/latex.php?latex=x%2Cy%5Cin+%5Cmathbf%7BZ%7D%5B%5Calpha%5D%2C+y%5Cne+0&bg=ffffff&fg=333333&s=0&c=20201002) , write x/y = q+s. Then the above observation tells us we can pick |s| < 1, or N(s) < 1. This gives: x = yq + ys, where N(ys) = N(y)N(s) < N(y). Thus N is still an Euclidean function for Z[(1+√-11)/2].
, write x/y = q+s. Then the above observation tells us we can pick |s| < 1, or N(s) < 1. This gives: x = yq + ys, where N(ys) = N(y)N(s) < N(y). Thus N is still an Euclidean function for Z[(1+√-11)/2]. turn out to be PIDs as well. Unfortunately, they are known to be non-Euclidean, so Euclid’s algorithm doesn’t work here.
turn out to be PIDs as well. Unfortunately, they are known to be non-Euclidean, so Euclid’s algorithm doesn’t work here.
 . Let I be the union of these sets. In general, union of ideals is not an ideal, but in this case I is (why?). By assumption, it is principal, I = <r>. Since r lies in the union of
. Let I be the union of these sets. In general, union of ideals is not an ideal, but in this case I is (why?). By assumption, it is principal, I = <r>. Since r lies in the union of 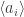 it must lie in some
it must lie in some  . Show that
. Show that 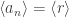 , and thus all subsequent ideals are also <r>.
, and thus all subsequent ideals are also <r>.
 to the set of non-negative integers such that
to the set of non-negative integers such that , we can find
, we can find  such that a = bq+r and either r=0 or f(r) < f(b).
such that a = bq+r and either r=0 or f(r) < f(b).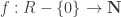 be an Euclidean function. For any non-zero ideal I of R, pick a non-zero element x of I such that f(x) is minimum. We claim I = <x>. Indeed, if y≠0 is in I, we can write y = qx+r, where r=0 or f(r) < f(x). Since r is in I, the second case is impossible by minimality of f(x). So y is a multiple of x and I is principal as desired. ♦
be an Euclidean function. For any non-zero ideal I of R, pick a non-zero element x of I such that f(x) is minimum. We claim I = <x>. Indeed, if y≠0 is in I, we can write y = qx+r, where r=0 or f(r) < f(x). Since r is in I, the second case is impossible by minimality of f(x). So y is a multiple of x and I is principal as desired. ♦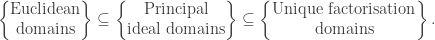
 ,
, , or
, or  .
. so
so  or
or 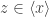 . In the first case, y = tx, so x = xtz. Since x ≠ 0 by assumption, tz = 1 so z is a unit. By symmetry, in the second case y is a unit. ♦
. In the first case, y = tx, so x = xtz. Since x ≠ 0 by assumption, tz = 1 so z is a unit. By symmetry, in the second case y is a unit. ♦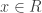 , let’s try to factor x. Either x=0, x=unit, x=irreducible or x=reducible. For the first three cases, there’s nothing to factor; for the last case, write x=yz where y and z are not units. Again, for each of y and z, we check if it’s irreducible; if yes, we’re done; otherwise, we factor it. Rinse and repeat.
, let’s try to factor x. Either x=0, x=unit, x=irreducible or x=reducible. For the first three cases, there’s nothing to factor; for the last case, write x=yz where y and z are not units. Again, for each of y and z, we check if it’s irreducible; if yes, we’re done; otherwise, we factor it. Rinse and repeat.
 and the process clearly doesn’t end. And none of the terms is a unit. So this is one ring where we don’t have finite factoring! ♦
and the process clearly doesn’t end. And none of the terms is a unit. So this is one ring where we don’t have finite factoring! ♦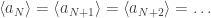 .
.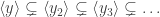
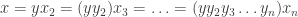 , each
, each  is irreducible.
is irreducible.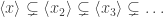 which must eventually terminate. Hence, the factorisation must end eventually. ♦
which must eventually terminate. Hence, the factorisation must end eventually. ♦ ,
,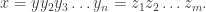

 where
where 

 forms a ring under matrix addition and multiplication, with unity given by the identity matrix. This is called the (full) matrix ring of R.
forms a ring under matrix addition and multiplication, with unity given by the identity matrix. This is called the (full) matrix ring of R.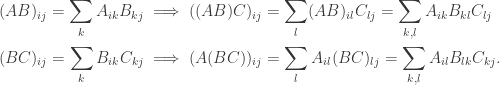
 .
. has no ideals other than {0} and itself.
has no ideals other than {0} and itself.![B := E[e, e]A E[f, f]](https://s0.wp.com/latex.php?latex=B+%3A%3D+E%5Be%2C+e%5DA+E%5Bf%2C+f%5D&bg=ffffff&fg=333333&s=0&c=20201002) then has only one non-zero entry left: B = Aef E[e, f]. Since D is a division ring, Bef is a unit and thus E[e, f] lies in <A>. Since E[i, e] E[e, f] E[f, j] = E[i, j], this also shows all E[i, j] lie in <A>. It clearly follows that <A> is the whole ring. ♦
then has only one non-zero entry left: B = Aef E[e, f]. Since D is a division ring, Bef is a unit and thus E[e, f] lies in <A>. Since E[i, e] E[e, f] E[f, j] = E[i, j], this also shows all E[i, j] lie in <A>. It clearly follows that <A> is the whole ring. ♦ , where R is not necessarily commutative, such that AB = BA = I, then we say A is invertible. In other words, A is invertible iff it is a unit in the ring of matrices.
, where R is not necessarily commutative, such that AB = BA = I, then we say A is invertible. In other words, A is invertible iff it is a unit in the ring of matrices.

 .
.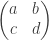 ? Should it be ad–bc, or da–bc, or …what?
? Should it be ad–bc, or da–bc, or …what?