
Introduction
In the previous article, we described the Schreier-Sims algorithm. Given a small subset 
![k_1, k_2, \ldots, k_m \in [n] = \{1, 2, \ldots, n\}](https://s0.wp.com/latex.php?latex=k_1%2C+k_2%2C+%5Cldots%2C+k_m+%5Cin+%5Bn%5D+%3D+%5C%7B1%2C+2%2C+%5Cldots%2C+n%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)

we have a small generating set 
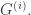
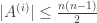
In this article, we will answer the following question.
Factorization Problem.
How do we represent an arbitrary representation
as a product of elements of
and their inverses?
If we can solve this problem in general, we would be able to solve a rather large class of puzzles based on permutations, e.g. Rubik’s cube and the Topspin puzzle. First, let’s look at the straightforward approach from the Schreier-Sims method.
Attempt
Recall that the Schreier-Sims method starts with 
![k_i \in [n]](https://s0.wp.com/latex.php?latex=k_i+%5Cin+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)

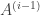

The problem with this approach is that since 

Minkwitz’s Algorithm
As far as we know, the first paper to solve the factorization problem is by T. Minkwitz in “An Algorithm for Solving the Factorization Problem in Permutation Groups” (1998). The idea is elegant. First, we replace the generating sets
Main Goal.
For each
, let
be the orbit
We wish to obtain a set
, indexed by
, such that
takes the base element

In other words, the element 

Minkwitz’s method replaces the sequence of sets 


To begin, we initialize 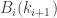
Next we run through words in 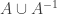
- Start with i = 0.
- Let
. Do we have an entry for
?
- If not, we let
- If yes, and w is shorter than the current word in
- Otherwise, let
Replace w with
and increment i then repeat step 2.
- If not, we let
Example
Let us take the example from the previous article, with 

Applying the Schreier-Sims algorithm, we obtain the following base and orbits:

From this, we deduce that the order of G is 5 × 4 × 3 × 3 × 2 = 360. Applying Minkwitz’s algorithm, we first initialize the table as follows:

Now consider the word ‘a’, which corresponds to g = (1, 5, 7)(2, 6, 8). This has no effect on 
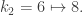

After running through all words of length 1, we arrive at the following table:

The first word of length 2 is ‘aa’, which corresponds to (1, 7, 5)(2, 8, 6), but this is just a-1, and we have already processed it.
The next word of length 2 is ‘ab’, which gives 
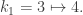

and proceed on to 


Further Improvements
The above method is quite effective for most random groups. However, the last few entries of the table may take a really long time to fill up. E.g. on the set:

the shortest word which takes 1 to n is given by 
One possible way out of this rut is to fill in entries of the table by looking at the group elements below the current row. To be specific, suppose the row for 
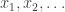
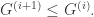


Optimization
To further optimize, note that sometimes a table entry gets replaced with a nice shorter word – it would be desirable to use this short word to update the other table entries.
Hence, we perform the following. For each row i, consider any two words w’, w” on that row. We take their concatenation w := w’w” and use it to update the entire table from row i onwards (by update, we mean: compute 
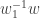
As this process is rather slow, we only update the table if either w’ or w” are of shorter length, compared to the last time we did this optimization.
Summary
Minkwitz’s paper suggests the following iterative procedure.
- Set a maximum word length l.
- For each word of short length, update the table as described earlier.
- If, at a certain row, the word length exceeds l, we bail out.
- For every s steps, do the following.
- Perform the above two enhancements: filling up and optimizing.
- Increase l, say, to (5/4)l.
Setting the word length is optional, but can speed things up quite a bit in practice. It prevents the initial s steps from filling up the table with overly long words, otherwise optimizing them will be costly. For further details, the diligent reader may refer to Minkwitz’s original paper, available freely on the web.
Outcome.
We applied this to the study of the Rubik’s cube group, and obtained a representation with maximum word length of 184 over all elements of the group. This is slightly worse than the result of 144-165 quoted in Minkwitz’s paper.
Case Study: Topspin Puzzle
The Topspin puzzle is a toy which consists of a loop with 20 labeled counters in it. In the middle of the loop lies a turntable which reverts the order of any four consecutive counters. This is what the puzzle looks like.

[ Photo from product page on Amazon. ]
Thus the group of permutations of the counters is generated by
a = (1, 2, 3, …, 20), b = (1, 4)(2, 3)
From the Schreier-Sims algorithm, we see that these two elements generate the full symmetric group 
To search for short words representing a given 
- let w be a short word in
;
- let
be the permutation for w;
- find the word w’ for
;
- thus ww’ is a word representing g.
We iterate over about 1000 instances of w and pick the shortest representation among all choices.
Example
Consider the transposition (1, 2). We obtain the following word:
a-1a-1b-1a-1b-1ab-1a-1b-1abab-1a-1a-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b-1a-1b
of length 43 (to be applied from right to left). This is a remarkably short word – for most random configurations we tried, the length of the word is >200.

Thank you for your article! The filling optimization is unclear to me, is it supposed to work as follows: in the example, we already have that ‘b’ takes 3 to 4. If in the generator for 8 we find a word that takes 4 to 8, then we can combine it with ‘b’ to find a word from 3 to 8. We could in theory take more than one such step to find new words.
EDIT: “If in the generator for _4_ we find a word that takes 4 to 8”