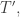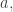Tableaux and Words
In our context, a word is a sequence of positive integers; concatenation of words is denoted by 
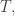
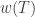
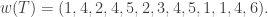
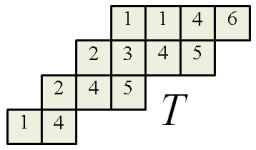
The following are quite easy to verify.
- If
is an SSYT, then it can be recovered from
- We pick the longest weakly increasing sequence starting from the first number; this forms the last row. Repeat with the next number to obtain the second-to-last row, etc. E.g. given (4, 5, 3, 3, 4, 6, 1, 2, 3, 3, 5, 7), we get a three-row SSYT comprising of (1, 2, 3, 3, 5, 7), (3, 3, 4, 6) and (4, 5).
- Not every word occurs as
- E.g. (1, 2, 1, 2) does not come from an SSYT.
- However, every word occurs as
elements of the sequence diagonally: 1st row and
-th square etc.
- In general, a skew SSYT
- E.g. for (1, 2), we can either take the SSYT (1, 2), or the skew diagram (2,1)/(1) and fill in 1, 2.


Words and Row Insertion
Next we formulate rules such that row-inserting (bumping) an entry 
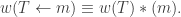
Suppose we have a row 
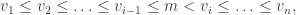
so that 


From this we obtain the first rule:
Rule R1. For any consecutive
in the word satisfying
, we switch

Next, to shift 
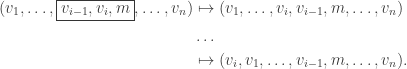
From here, we obtain the second rule:
Rule R2. For any consecutive
, we switch

Example
Suppose we insert 

Now we wish to revert the inserting process, so we will consider reverse of R1 and R2 as well, denoted by R1′ and R2′ respectively.
Summary of Rules
Given a consecutive triplet
or
: no change;
: switch to
by R1;
: switch to
by R2;
: switch to
: switch to
One checks that these cases are disjoint and cover all possibilities. Two words are said to be Knuth-equivalent, written as
if we can obtain one from the other via the above 4 operations.
Mnemonic
The following diagram helps us in recalling R1 and R2.

Consequences of Equivalence
From our construction of R1 and R2, we immediately have:
Proposition 1.
.
The following result is less trivial.
Proposition 2. If
is obtained by sliding an inner corner of skew SSYT
Proof
Clearly, horizontal sliding does not change the word, so we will only consider vertical sliding. By trimming off excess elements in the two rows:
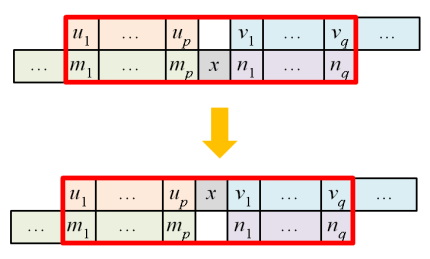
we may assume the two rows have the same length. We will prove that the corresponding words are Knuth-equivalent via induction on p. Write 

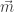
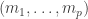

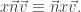
- Imagine performing row insertion for
into
Since
this bumps out
and we transform
to
- Inserting
into this row then bumps out
and we obtain
Moving on, we eventually obtain
as desired.

Now assume 
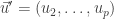

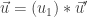
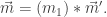

Inserting 

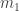

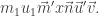
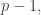
On the other hand, on the RHS above we insert 
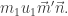
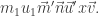
Corollary. Every word
is Knuth-equivalent to
Proof
Indeed write 


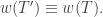
This
Additional Result
Finally, the following result is interesting but will not be used.
Lemma. If the skew tableau
by a horizontal or vertical line (where
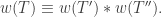
Proof
In the case of horizontal cut, we in fact have 
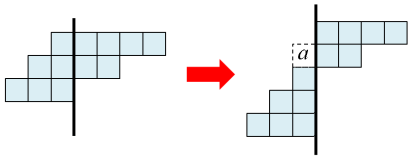
Start removing the inner corners from