[ Prerequisites : basic linear algebra, matrices and determinants. ]
Eigenvalues and eigenvectors are often confusing to students the first time they encounter them. This article attempts to demystify the concepts by giving some motivations and applications. It’s okay if you’ve never heard of eigenvectors / eigenvalues, since we will take things one step at a time here.
Note: all vectors are assumed to be column vectors here, and a matrix acts on a vector via left multiplication.
Consider the matrix  . We know mathematically what it does: it takes a (column) vector v = (x, y) to w = (3x+y, x+3y). But what’s the geometry behind it? If we take the circle C with radius 1 and centre at origin, then the matrix maps C to the ellipse C’ as follows:
. We know mathematically what it does: it takes a (column) vector v = (x, y) to w = (3x+y, x+3y). But what’s the geometry behind it? If we take the circle C with radius 1 and centre at origin, then the matrix maps C to the ellipse C’ as follows:

(Image from wolframalpha.com)
As for how we obtained the equation 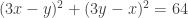 , that’s left as an exercise. 🙂 From the diagram, it should be clear that the matrix M “stretches” vectors along the diagonals. Specifically, let’s tilt our head 45° and pick the basis comprising of
, that’s left as an exercise. 🙂 From the diagram, it should be clear that the matrix M “stretches” vectors along the diagonals. Specifically, let’s tilt our head 45° and pick the basis comprising of  and
and  . Then we get
. Then we get  and
and  . Since {v, w} forms a basis of the plane, we get:
. Since {v, w} forms a basis of the plane, we get:
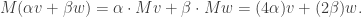
Thus geometrically, M behaves very much like the diagonal matrix  . We will expound on this now: writing
. We will expound on this now: writing  , we get
, we get  , where D is the diagonal matrix above. Since {v, w} forms a basis, the matrix Q is invertible so:
, where D is the diagonal matrix above. Since {v, w} forms a basis, the matrix Q is invertible so:
 .
.
More generally, we say that matrices M and N are similar if there exists an invertible matrix Q such that 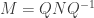 . For a given matrix M, the process of finding a similar diagonal matrix D is called diagonalisation. Generally, the fact that M is similar to a diagonal matrix can be useful, both conceptually and computation-wise.
. For a given matrix M, the process of finding a similar diagonal matrix D is called diagonalisation. Generally, the fact that M is similar to a diagonal matrix can be useful, both conceptually and computation-wise.
Exercise 1 : if M and N are similar, as are M’ and N’, does that mean M+M’ and N+N’ are similar?
From we get 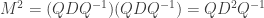 . More generally, one can show by induction that
. More generally, one can show by induction that  in general. This spells good news for us: since D is diagonal, its powers can be easily evaluated:
in general. This spells good news for us: since D is diagonal, its powers can be easily evaluated:  . Putting it all together with
. Putting it all together with  , we get a closed form:
, we get a closed form:
 .
.
Example: Binet’s Formula
This is (yet) another derivation of Binet’s formula for the Fibonacci sequence:  for
for  . If we consider the column vector
. If we consider the column vector  , then the recurrence
, then the recurrence 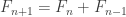 translates to the following matrix relation:
translates to the following matrix relation:
 .
.
Thus, we get 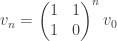 . This strongly suggests diagonalising the matrix
. This strongly suggests diagonalising the matrix  .
.
To do so, we need to find vectors v and w such that  and
and  for some scalar values
for some scalar values  . Of course, v and w are non-zero vectors here, so this means the matrix
. Of course, v and w are non-zero vectors here, so this means the matrix  (where i = 1, 2) maps some non-zero vector to zero. In other words,
(where i = 1, 2) maps some non-zero vector to zero. In other words,  . But we can expand via the determinant formula to obtain:
. But we can expand via the determinant formula to obtain:
 .
.
Solving for this quadratic equation we get  and
and  , which explain the terms in Binet’s formula. We’ll leave the rest to the reader.
, which explain the terms in Binet’s formula. We’ll leave the rest to the reader.

More generally, if p(x) is any polynomial with real coefficients, then we can write 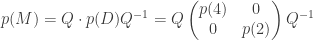 . For example, if
. For example, if  , then we have:
, then we have:
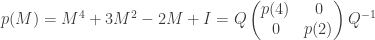
and evaluate accordingly.
And why stop at polynomials? Why not infinite power series? Indeed, recall the Taylor expansion for the exponential function 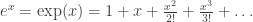 . We can define it for matrices also: for any matrix M, let us write:
. We can define it for matrices also: for any matrix M, let us write:
 .
.
Infinite sums are always rather pesky since we’re not sure if they converge. This is even more so for matrices. Fortunately, since we have the diagonalisation , we even know exactly what it converges to:
 .
.
Exercise 2. Prove that for any real numbers t and s, 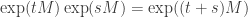 .
.
Exercise 3. Is it true that  for any two matrices?
for any two matrices?
Exercise 4. Define cos(A) and sin(A) for an arbitrary matrix A. [ Hint: if you know complex numbers, there’s no need to write them in Taylor expansion. ] Is it true that  for any matrix A? What about
for any matrix A? What about 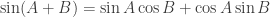 ?
?
Clearly we can generalise the above discussion to n × n matrices in general. Specifically, let M be a square matrix. If there is a scalar λ and a non-zero vector v such that 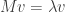 , then we say λ is an eigenvalue with corresponding eigenvector v.
, then we say λ is an eigenvalue with corresponding eigenvector v.
Next, M is diagonalisable if we can write for some invertible matrix Q and diagonal matrix D. E.g. if M is a 4 × 4 matrix and we can diagonalise it as:
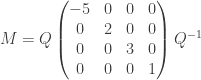 ,
,
then we know that the general entries of  can be written as a fixed linear combination of the powers (-5)n, 2n, 3n, 1n=1. In particular, when n is large, the absolute values of the entries are approximately a constant times 5n.
can be written as a fixed linear combination of the powers (-5)n, 2n, 3n, 1n=1. In particular, when n is large, the absolute values of the entries are approximately a constant times 5n.
In short, if we know the largest eigenvalue λ of a matrix, then we can approximate the size of the entries of via a constant times 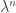 . For this reason, we have a special name for this value. The spectral radius of a matrix M is defined to be the largest |λ| among all eigenvalues λ of M.
. For this reason, we have a special name for this value. The spectral radius of a matrix M is defined to be the largest |λ| among all eigenvalues λ of M.
As mentioned earlier, to diagonalise an n × n matrix M in general, we first write MQ = QD for some diagonal matrix D. If we break the matrix Q into column vectors 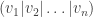 , then this translates to:
, then this translates to:
 ,
,
for some scalar values  . But this just means each
. But this just means each  is a non-zero vector satisfying
is a non-zero vector satisfying  so the matrix
so the matrix  is singular for each i. This means the eigenvalues of M are precisely the values of λ such that
is singular for each i. This means the eigenvalues of M are precisely the values of λ such that 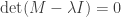 !
!
It turns out not all matrices are diagonalisable. But most of the time they are:
Theorem. If an n × n matrix M has n distinct eigenvalues (i.e. the equation has no repeated root), then M is diagonalisable.
Proof. Let the n distinct eigenvalues be  , i = 1, 2, …, n. Each eigenvalue must have some corresponding eigenvector . Let
, i = 1, 2, …, n. Each eigenvalue must have some corresponding eigenvector . Let  . The relation
. The relation  then says
then says 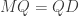 where D is the diagonal matrix with diagonal entries
where D is the diagonal matrix with diagonal entries 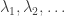 .
.
Thus, we only need to prove Q is invertible, or equivalently, that  are linearly independent. To that end, suppose they are linearly dependent. We re-order the eigenvectors and eigenvalues and drop extraneous terms such that:
are linearly independent. To that end, suppose they are linearly dependent. We re-order the eigenvectors and eigenvalues and drop extraneous terms such that:

for some non-zero scalar values ci and k ≤ n is as small as possible. Now let M act on both sides. Using the fact that 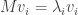 , we get:
, we get:

Multiplying the first equation by 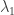 and taking the difference, we thus get an even shorter relation with smaller k. This contradicts the minimality of k. ♦
and taking the difference, we thus get an even shorter relation with smaller k. This contradicts the minimality of k. ♦
Thus, if one picks some random matrix with random entries, the result is almost certainly diagonalisable.
Exercse 5. Prove that the matrix  is not diagonalisable. Write the entries of in closed form.
is not diagonalisable. Write the entries of in closed form.


